친구가 알려준 웹 크롤링을 연습해보려고
가끔 들어가서 보던 영진위 통합전산망 사이트에서 정보를 긁어와봤다!
나도 구글링으로 도움을 많이 받았는데,
누군가에게 도움이 되면 좋겠다 :D
Google colab 이용 했다..
고쳐야할 것도 좀 있긴한데, 주석은 나중에 시간 될 때 달아보려고 한다.
대상되는 사이트는 아래와 같이 생겼다.
영화의 목록이 총 몇개인지는 알 수 없으나, 표 하나를 온전히 긁어내려면
더보기를 계속 눌렀어야 했다.

추가로, 영화 코드 정보도 함께 얻고 싶었지만
영화코드는 영화를 클릭해서 가져오거나, 또는 html 코드 안에 있는 것을 가져와야 했다.
html 코드 안에 있는 것을 가져오는게 더 수월하다고 판단했다.
html 코드를 보려면, 크롬 브라우저에서 html 확인을 원하는 부분에 마우스를 대고
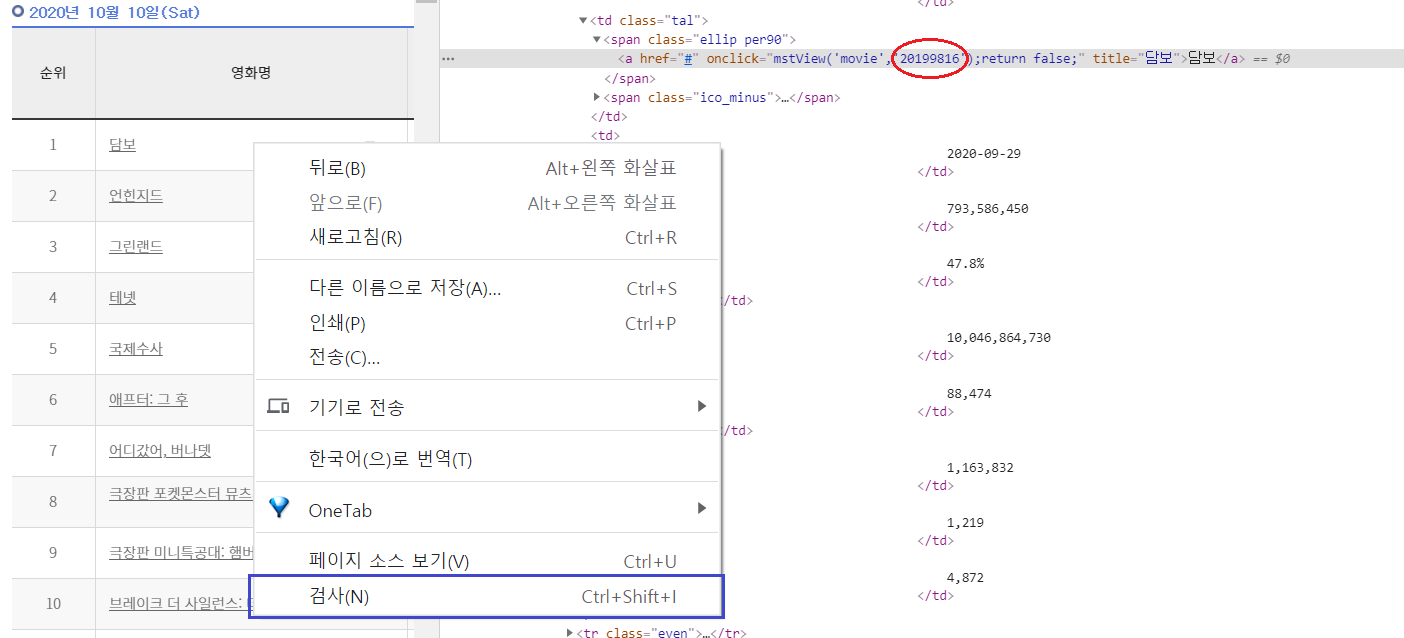
마우스 우클릭 > 검사(N)을 누르면 된다.
영화 [담보]의 정보를 확인해보았고, 내가 확인하고 싶은 영화 코드는
아래 이미지의 붉은 동그라미 표시한 '20199816' 이다.
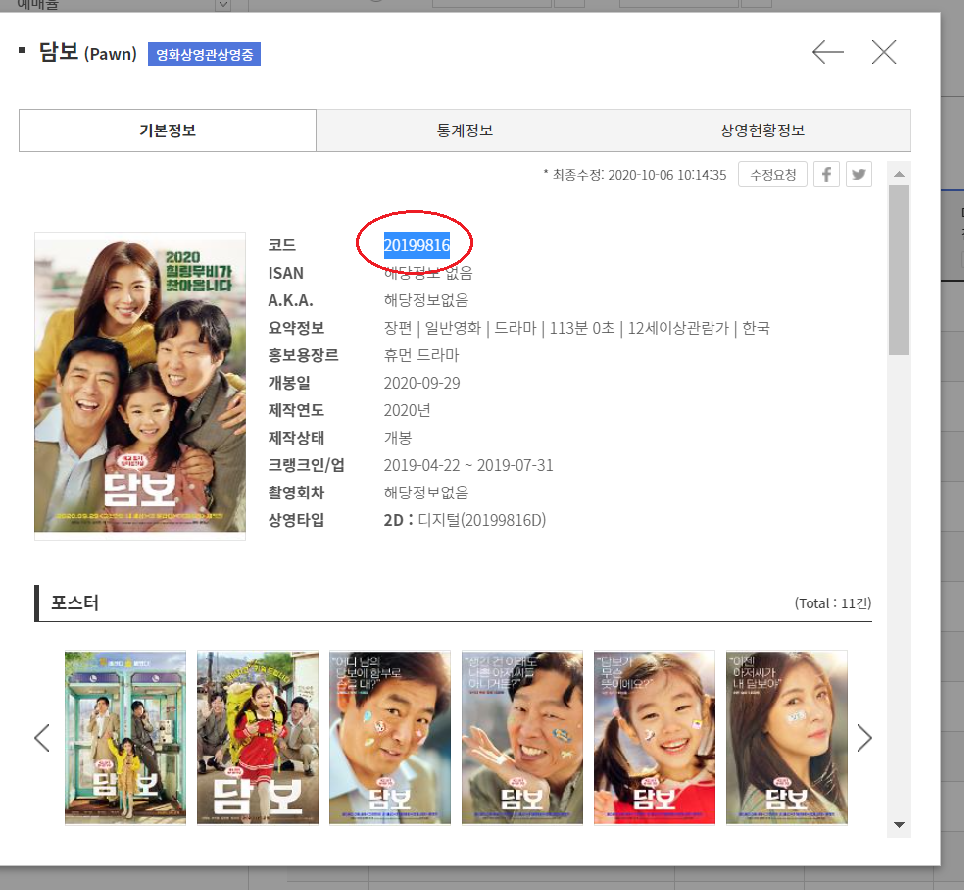
그냥 [담보] 영화를 클릭해도 아래와 같이 영화코드를 확인할 수 있긴 하지만,
코드가 더 복잡해질 것 같았다.
작업 내용들인데, 언젠가 주석이나 설명을 달아보겠다..
# 일단 import 해야할 것들
!pip install selenium
!apt-get update # to update ubuntu to correctly run apt install
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
import sys
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver')
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
#wd.get("https://www.webite-url.com")
pip install bs4
#필요한 패키지들
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
import time
import re
import csv
#참고하고자하는 사이트 url movie_url = 'http://www.kobis.or.kr/kobis/business/stat/boxs/findDailyScreenTicketList.do'
wd.get(movie_url)
for page_num in range (1,20):
wd.find_element_by_xpath('//*[@id="btn_0"]').click()
time.sleep(0.5)
td_totScrnCnt = wd.find_elements_by_id('td_totScrnCnt')
td_movie = wd.find_elements_by_id('td_movie')
td_rank = wd.find_elements_by_id('td_rank')
td_totScrnCnt[100].text
rank=[] title=[] screen=[] rank=[0]*100 title=[0]*100 screen=[0]*100 for rk in range(0,100): rank[rk] = td_rank[rk].text title[rk] = td_movie[rk].text screen[rk] =td_totScrnCnt[rk].text
data=[] for i in range(0,100) : data.append([rank[i],title[i],screen[i]]) data
fin_data = pd.DataFrame(data, columns = [ 'Rank', 'title', 'screen'])
fin_data
fin_data['rm'] = np.arange(len(fin_data))+1
from google.colab import drive
drive.mount('drive')
fin_data.to_csv('fin_data.csv')
!cp fin_data.csv 'drive/My Drive/'
wd.find_elements_by_link_text('mstView')
td_totScrnCnt = wd.find_elements_by_id('td_totScrnCnt')
td_movie = wd.find_elements_by_id('td_movie')
td_rank = wd.find_elements_by_id('td_rank')
td_movie[0].get_attribute('innerHTML')
td_movie[0].get_attribute('innerHTML').find('mstView')
mv_code = []
mv_code = [0]*100
for i in range(0,100) :
mv_code[i] = td_movie[i].get_attribute('innerHTML')[
td_movie[i].get_attribute('innerHTML').find('mstView')+17:
td_movie[i].get_attribute('innerHTML').find('mstView')+25]
data=[] for i in range(0,100) : data.append([rank[i],title[i],mv_code[i],screen[i]]) data
fin_df = pd.DataFrame(data, columns =['rank','movie_nm','movie_cd','on_screen'])
fin_df.to_csv('movie_list.csv')
!cp fin_df.csv 'drive/My Drive/'

더보기를 눌러야만 가져올 수 있었던 11위 이하의 영화정보와,
내가 가져오고 싶어하던 영화코드도 가져와진 것을 알 수 있다!
'언어 > Python' 카테고리의 다른 글
| [python] CES 뉴스 크롤링 /csv 파일명에 날짜 지정하기 (0) | 2021.01.08 |
|---|---|
| [Python] CES 2021 Awards 수상작 크롤링 (0) | 2021.01.07 |
| [Tensorflow] 텐서플로우 개발자 자격 시험 합격 후기 (20) | 2020.12.12 |
| [Tensorflow] 자격시험 공부용 Colab 예제 링크 모음 (0) | 2020.11.28 |